
- H.264 Intra Coding
- Overview of the H.264 codec pipeline
- Video Coding Overview
- Image Compression Techniques
- RGB, YUV, and Color Spaces Part 2
- RGB, YUV, and Color Spaces

Note that if the inter-prediction for a particular macroblock works perfectly (i.e., the residual after quantization is all 0s), the macroblock is marked as a “skip”. Otherwise, larger partition sizes would lead to fewer bits for encoding the motion vector and the reference frames, but could lead to more bits spent in encoding the residual (actual partition – motion predicted partition) for partitions with high detail. On the other hand, choosing smaller partition sizes leads to more bits spent in encoding the motion vector and reference frames, but potentially fewer bits in encoding the residual. There are several algorithms to find the optimal split (into partitions and sub-partitions), but those are beyond the scope of this video coding series.
Also, the chrominance components of a macroblock are split into partitions in similar ways. For example, for a YCbCr422 input, the macroblock is of size 16×8 for Cb, Cr components. This block can be inter-predicted as 1 16×8 block, 2 8×8 blocks. Each 8×8 block can then be inter-predicted in several ways as described above.
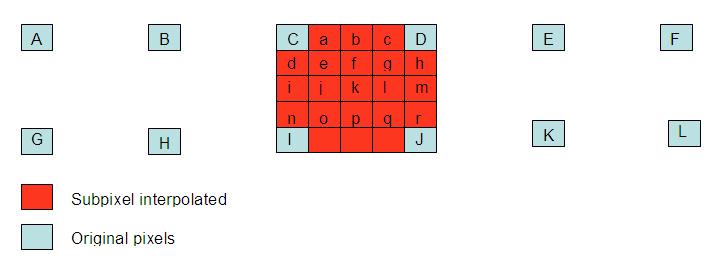
For a given partition (or sub-partition), a similar-sized partition in a given reference frame is used for prediction. The offset of the partition in the reference frame with respect to the given partition is specified by a two-dimensional motion vector (see the picture below). In MPEG1-3, the resolution of the motion vectors was half-a-pixel (for example, (0.5, 1.5) would be a valid motion vector). For integer-valued motion vectors, the partition in the reference frame actually exists as real pixels. For fractional integer values like (0.5, 1.5), the partition in the reference frame has to be constructed from the neighboring (integer-valued) real pixels (as shown in picture ‘c’ below). In H.264, a 6-tap filter (weighted linear average of the 6-pixels on the same horizontal or vertical lines) is used to compute the half-pixel values (Note that for some positions, multiple possibilities arise; see here for more details).

In MPEG4-ASP (Advanced Simple Profile) and H.264, the resolution of motion vectors is quarter pel (quarter of a pixel). Once the half-pixel values are computed, the quarter pixel values are computed using a bilinear interpolation (an equation of the form v = a + b * x + c * y + d * x* y where x and y are hpel values, a, b, c, d are co-efficients, and v is the computed qpel value; hpel refers to half-pixel and qpel refers to quarter-pixel).
Note that motion vectors themselves are not transmitted in full for all the partitions. Motion vectors themselves are predicted on the basis of motion vectors of neighboring (sub-)partitions. In particular, the median value of the motion vectors, of the partitions immediately above, immediately to the left, and diagonally to the above and right, is used as a prediction for the motion vector of the partition under consideration (Note that this predictor is different when “uneven” partitions like 16×8 blocks are used, or when some of the motion vectors are unavailable). You can check the ffmpeg implementation here for more details.
References:
— http://mrutyunjayahiremath.blogspot.com/2010/09/h264-inter-predn.html
— http://en.wikipedia.org/wiki/Motion_compensation
— http://en.wikipedia.org/wiki/Bicubic_interpolation
— http://en.wikipedia.org/wiki/Qpel
— http://sonnati.wordpress.com/2007/10/29/how-h-264-works-part-ii/
— http://en.wikipedia.org/wiki/Finite_impulse_response
— http://www.design-reuse.com/articles/18642/h-264-avc-hdtv-motion-compensation-soft-ip.html
— http://www.h265.net/2010/12/analysis-of-coding-tools-in-hevc-test-model-hm-inter-prediction.html
— Discussion of half-pel and quarter-pel here.
— http://x264dev.multimedia.cx/archives/164
— http://ffmpeg.org/doxygen/trunk/group__mv.html
— http://en.wikipedia.org/wiki/Inter_frame
— http://www.cic.unb.br/~mylene/PI_2010_2/ICIP10/pdfs/0002037.pdf
